1. Google SEO 란?
- SEO는 Search Engine Optimization의 약자이다. 직역하자면 검색엔진 최적화라는 뜻인데, 검색엔진에서 상단에 노출되게 하기위한 방법이라고 생각하면 된다. 우리나라에서 가장 많이 쓰이는 검색엔진은 구글, 네이버인데, 그 중 구글의 검색엔진 최적화를 위한 방법을 소개하고자 이 포스트를 작성하게 되었다.
- 지난 1달간 구글 검색엔진 최적화를 위해서 여러 가지 작업을 진행해봤다. 그런데 생각보다 쉽지 않았다. 상당히 많은 것들을 해줘야 구글 검색 엔진에서 상위권에 노출될 수 있는데, 기본적인 것들만 소개해보겠다.
- 이 글의 대상자 : 구글 SEO에 대해 처음 알아보는 사람
2. robots.txt
- 구글 검색엔진에서의 노출은 기본적으로 구글봇이라는 크롤러 1 가 여러 웹사이트를 크롤링하면서 모은 정보의 순위를 매기는 방식으로 진행된다.
- 모든 크롤링은 각 사이트의 robots.txt를 참고하여 진행되는데, robots.txt에 표시된 정보에 따라서 크롤링을 가능, 불가능하게 설정할 수 있다.
- 이 블로그의 robots.txt는 아래와 같다.robots.txt
# Allow crawling of all content
User-agent: *
Allow: /
Sitemap: https://sadocode.github.io/sitemap.xml
- User-agent : 크롤러를 의미한다. 값을 * 로 하면 모든 크롤러를 의미한다. 구글봇의 이름은 Googlebot이다.
- Allow : 크롤링을 허락할 웹사이트의 path를 의미한다. 만약에 어느 부분만 크롤링하길 원한다면 원하는 path를 설정하면 된다.
- Disallow : 크롤러가 크롤링하지 못 하는 path를 입력한다. 위의 robots.txt에는 Disallow를 설정하지 않고, Allow : / 로 설정하였으므로, 모든 path의 크롤링을 허용하겠다는 의미이다.
- Sitemap : 웹사이트의 sitemap.xml의 path를 표시해주는 부분이다. 크롤러는 sitemap을 보고 sitemap에 표시된 페이지들을 크롤링한다.
- 아래와 같은 방식으로 robots.txt를 작성할 수도 있다.
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: Twitterbot
Allow: /image
User-agent: *
Disallow: /
Sitemap: https://sadocode.github.io/sitemap.xml
- 위의 robots.txt는 구글봇, 빙봇에게는 사이트의 크롤링을 모두 허용, 트위터봇은 /image에만 크롤링을 허용하고, 나머지 크롤러들의 크롤링은 막겠다는 의미이다.
- 각 기업, 검색엔진의 크롤러를 검색을 통해 확인해서 적용하는 것을 추천한다. 웹 크롤러 - 위키백과, 우리 모두의 백과사전
3. sitemap.xml
- 구글봇은 robots.txt를 통해 크롤링 가능한 부분을 확인한 후에 sitemap을 확인한다. sitemap에 표시된 페이지를 참고해서 크롤링을 진행한다.
- 이 블로그의 sitemap.xml은 아래와 같다.

- urlset : 필수. 파일을 캡슐화하고, 현재 프로토콜의 표준을 참조한다.
- url : 필수. 각 URL 항목의 상위 태그.
- loc : 필수. 페이지의 URL
- lastmod : 최종 수정 시각
- changefreq : 문서 update 주기. 값으로는 always, hourly, daily, weekly, monthly, yearly, never가 올 수 있다. 검색엔진에 제공하는 보편적인 정보로 검색 엔진(구글)에서 크롤링하는 정확한 빈도와는 관련이 없을 수도 있다고 한다.
- priority : 값으로는 0.0 ~ 1.0이 올 수 있다. 검색엔진이 사이트 내에서 크롤링할 페이지의 우선순위를 정할 때에 고려하는 값이다. 페이지 별로 값을 다르게 줘서 중요도가 높은 페이지가 검색엔진에 더 노출될 확률을 올릴 수 있다. (모든 페이지를 1.0으로하는 것은 모든 페이지를 0.1로 한 것과 똑같다.)
- sitemap 참고 페이지
4. Google Search Console
- robots.txt, sitemap.xml을 등록한다고 구글에 검색되는 것은 아니다. 구글에 검색되려면 구글 서치 콘솔에 내 사이트를 등록해줘야 한다. 구글 서치 콘솔에서 시키는대로 사이트 인증을 하고, 본인 사이트의 sitemap.xml의 URL을 등록하면 된다. 기억하기론 하루 정도 지나고 나니까 구글봇이 사이트를 크롤링하기 시작했던 것 같다.
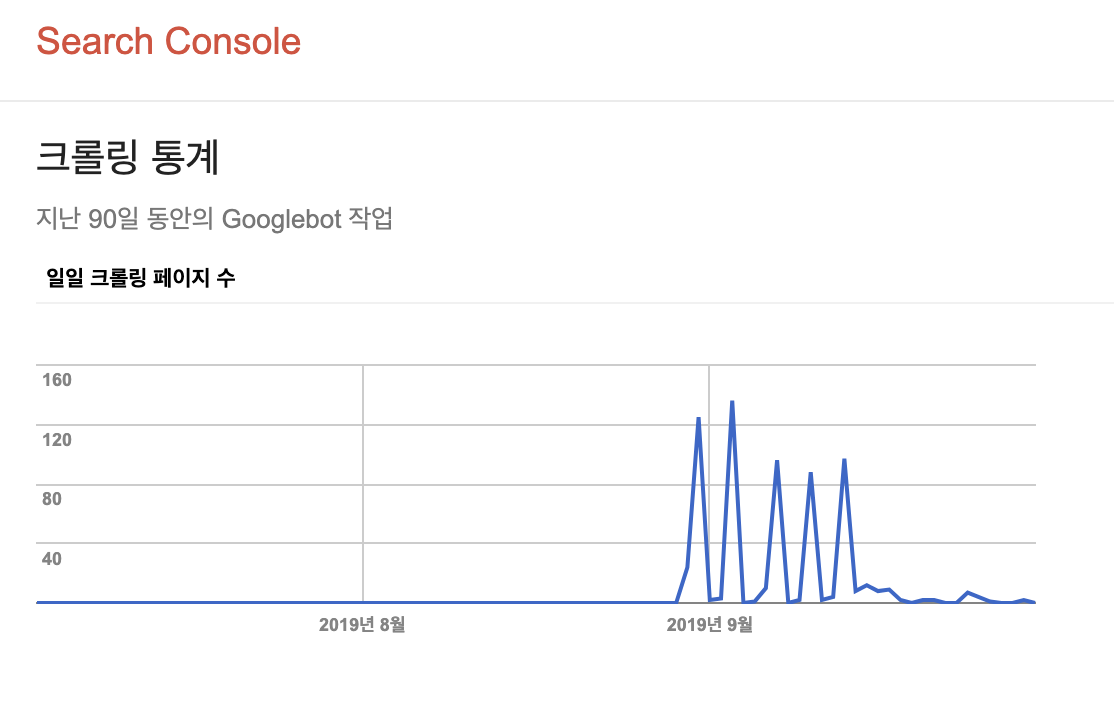
- 위의 이미지는 robots.txt, sitemap.xml을 설정하고 Google Search Console에 사이트를 등록하고 난 뒤에 구글봇이 이 사이트를 크롤링한 횟수를 나타낸다. 서치 콘솔에 등록하기 전에는 0이었던 크롤링 횟수가 변화했음을 알 수 있다.
- 즉, 무조건 Google Search Console에 등록해야지만 구글에 내 사이트가 검색가능하다!!
5. 추가 내용
이 포스트의 내용은 정말 구글검색엔진에 노출되기 위해 기본적으로 해줘야하는 부분이다. 따라서 사이트를 검색엔진 상위권에 올리고 싶으면, 훨씬 더 많은 것들을 해줘야 한다. 뉴스, 신문 사이트들을 대상으로 조사를 해봤는데 매일경제가 언론사 규모에 비해 상당히 구글 검색엔진 최적화가 잘 되어 있는듯하다. SEO를 어떤 식으로 하면 좋을 지 궁금하면 참고해보는 것도 좋을 것 같다. 매일경제.
5.1 Google SEO 추가 정보
구글에서 공개한 내용에 따르면 검색엔진에 상위 노출되기 위한 결정적 요소 3가지는 다음과 같다.
- 키워드 수와 위치
- 웹페이지의 생성 시기
- 웹페이지로 들어오는 인바운드 링크의 수
그 밖에 중요한 요소는 다음과 같다고 한다.
- 모바일 친화적인 웹페이지
- 보안 프로토콜(HTTPS)
- robots.txt, sitemap.xml
- title과 meta description 태그
- 소셜 메타 태그
- 이미지 태그 최적화
- 콘텐츠 최적화
-
크롤러 - 웹사이트를 방문하여 각종 정보를 자동으로 수집하는 프로그램. 검색엔진의 근간이 된다. 크롤링 - 웹사이트를 방문하여 각종 정보를 수집하는 행위. ↩